🎨
Pure SEGA Editing with DDPM Inversion
Using DDPM purely for inversion (i.e. target prompt=””), such that a perfect reconstruction of the original image is achieved, and editing is performed by adding SEGA edit concepts.
Recent large-scale text-guided diffusion models provide powerful image generation capabilities. Currently, a significant effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. However, editing proves to be difficult for these generative models due to the inherent nature of editing techniques, which involves preserving certain content from the original image. Conversely, in text-based models, even minor modifications to the text prompt frequently result in an entirely distinct result, making attaining one-shot generation that accurately corresponds to the user's intent exceedingly challenging. In addition, to edit a real image using these state-of-the-art tools, one must first invert the image into the pretrained model’s domain - adding another factor affecting the edit quality, as well as latency. In this overview, we propose LEDITS- a combined lightweight approach for real-image editing, incorporating the Edit Friendly DDPM inversion technique with Semantic Guidance, thus extending Semantic Guidance to real image editing, while harnessing the editing capabilities of DDPM inversion. This approach achieves versatile edits, both subtle and extensive as well as alterations in composition and style, while requiring no additional training and optimization nor extensions to the architecture.

The exceptional realism and diversity of text-guided diffusion models in image synthesis have sparked significant interest, leading to ongoing research on utilizing these models for image editing. Recently, intuitive text-based editing showcased the ability to effortlessly manipulate synthesized images using text alone. In a recent work by Brack et al. the concept of semantic guidance (SEGA) was introduced for diffusion models, demonstrating sophisticated image composition and editing capabilities without the need for additional training or external guidance. Text-guided editing of a real image with state-of-the-art tools requires inverting the given image and textual prompt. That is, finding a sequence of noise vectors that produces the input image when fed with the prompt into the diffusion process. A novel inversion method for DDPM was proposed by Huberman-Spiegelglas et al., which computes noise maps that exhibit stronger image structure encoding and generates diverse state-of-the-art results for text-based editing tasks. In this work we demonstrate the extended editing capabilities obtained from combining the two techniques.

Our approach for the integration consists of a simple modification to the SEGA scheme of the diffusion denoising process. This modification allows the flexibility of editing with both methods while still maintaining complete control over the editing effect of each component. First, we apply DDPM inversion on the input image to estimate the latent code associated with it. To apply the editing operations, we perform the denoising loop such that for each timestep, we repeat the logic used in SEGA but with the DDPM scheme, using the pre-computed noise vectors.
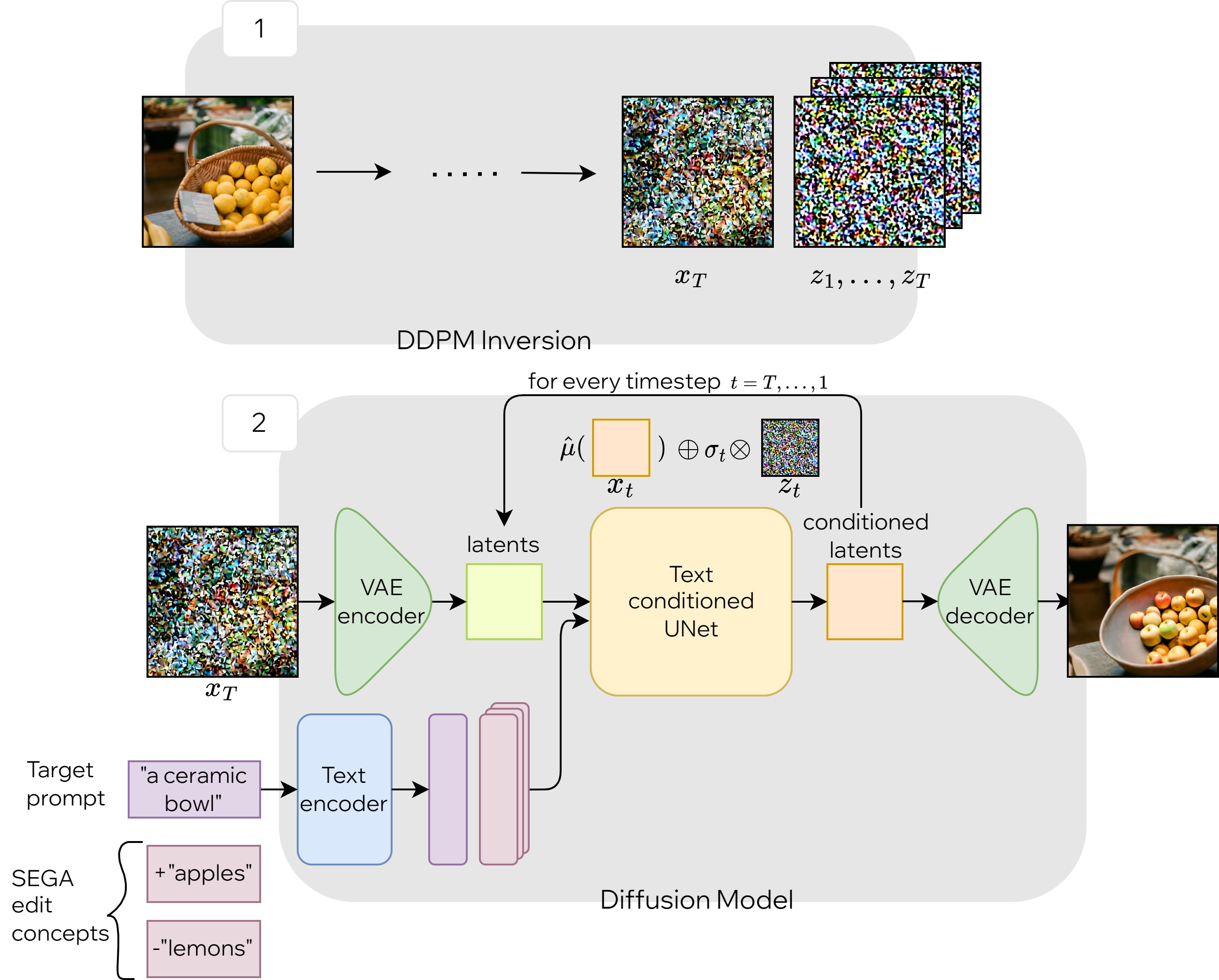
Using DDPM purely for inversion (i.e. target prompt=””), such that a perfect reconstruction of the original image is achieved, and editing is performed by adding SEGA edit concepts.
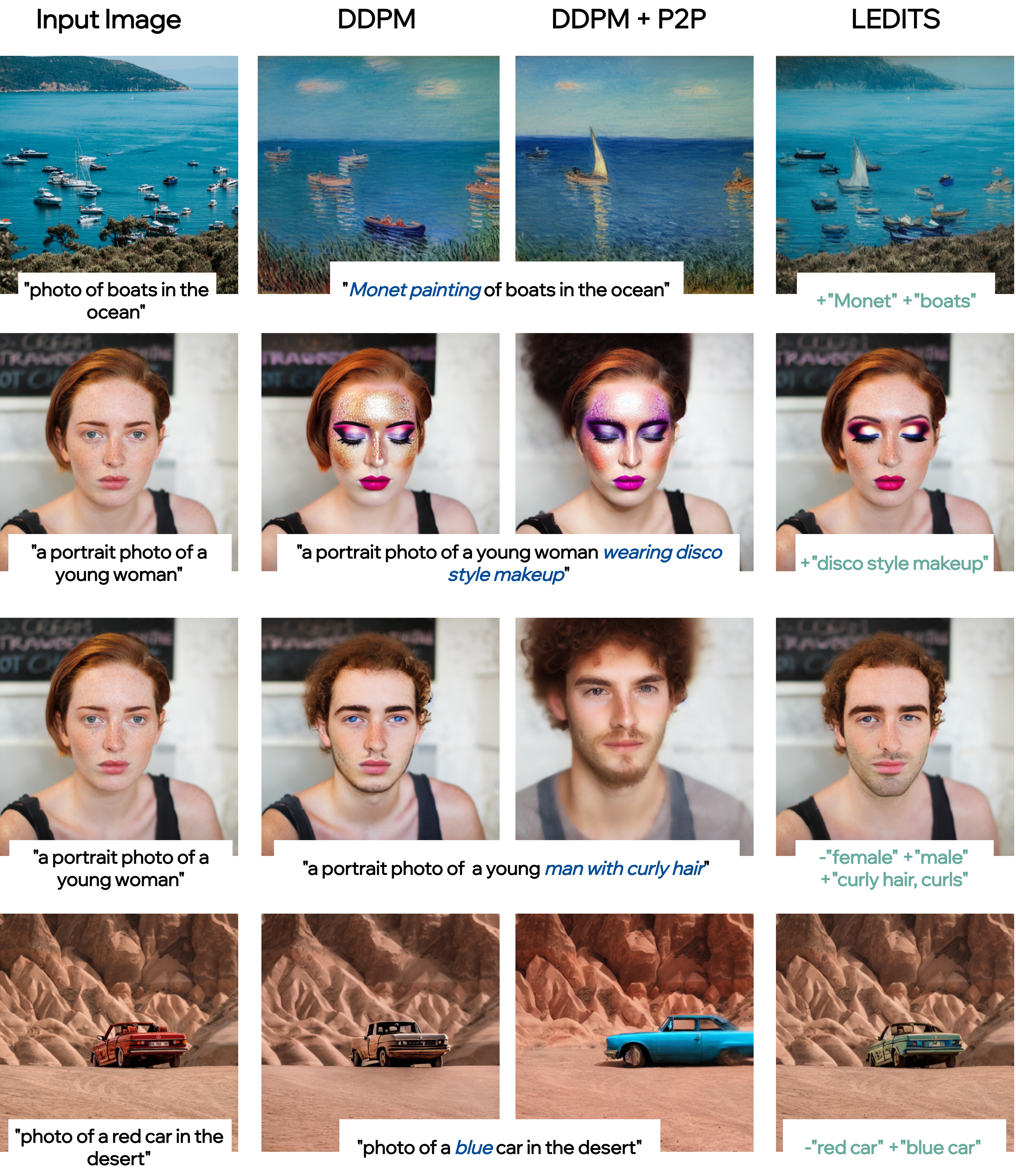
Perform two editing operations simultaneously by choosing a target prompt that reflects a desired edited output, in addition to adding SEGA edit concepts.
LEDITS adds another layer of flexibility in tuning the effect of the desired edit, balancing between preserving the original image semantics and applying creative edits
Multiple edit operations can be applied independently and simultaneously with a target prompt (reflecting one or more edit operations) and SEGA concepts (each reflecting an edit operation)
The combined control can compensate for the limitations of one approach or the other in various cases
@article{tsaban2023ledits,
author = {Linoy Tsaban and Apolinário Passos},
title = {LEDITS: Real Image Editing with DDPM Inversion and Semantic Guidance},
year = {2023},
eprint = {2307.00522},
archivePrefix = {arXiv},
primaryClass={cs.CV}
}